
In the last part of this post, I gave a general overview of Raft followed by Leader Election algorithm. We now need to discuss, how leader does the consistent replication of log onto the follower nodes, few more safety properties, and constraints on the election mechanism.
Log Replication
For now let’s assume that client requests are write-only requests. Each request is a command to be executed by the replicated state machines on all the nodes. The leader node needs to coordinate such request by writing an entry for the request into its local log, and replicating it on the logs of follower nodes in the cluster. The goal is to keep the logs of all nodes consistent with each other. This will ensure that all of the deterministic state machines will execute the commands (log entries) in the same order, and move to a consistent output state.
Each entry in a log:
- Contains the client specified command/input.
- Has an index to identify the position of entry in the log. Index starts from 1.
- Has a term # to logically identify when the entry was written. I will discuss how this is used to detect inconsistencies between the logs.
Upon receiving the client request, the leader creates an entry, and appends it to the local log. It then parallely issues AppendEntries RPC to all the follower nodes asking them to append the entry into their respective logs. An entry is committed once it is replicated on the logs of majority of servers. Only after an entry is committed, it is safe to be processed by the state machines of the servers from their respective logs.
How do we know that an entry has been committed and is ready to be applied on the state machine ?
The leader node gets a response (success/failure) for some/all of the AppendEntries RPCs it sent out. Once it hears back “success” from majority of followers, it designates the log entry to be committed, applies the command from the entry to its local state machine, and returns the result back to the client. A committed entry is guaranteed to be eventually executed by the state machine of each follower the entry was replicated to. Each server maintains “highest committed log entry index” known to it. During AppendEntries RPC communication with the follower nodes, the leader exchanges its commit index to let the followers know about the committed entries.
Maintaining Consistent Logs
We need to have the following invariant:
If an entry in log of server S1 (leader or follower) has the same index and term as an entry in the log of another server S2, then:
- Both the log entries contain the same command.
- Both the servers have identical logs for preceding entries.
This gives rise to the Log Matching safety property:
Safety Property 3 – If two logs contain an entry with same index and term, then both logs have identical entries up to the given index.
Let’s see how we ensure the above property. If a system doesn’t have any server failures/crashes or temporary glitches, we can imagine that logs on all the servers will stay consistent. The leader and the follower nodes will always be available, the leader will receive successful acknowledgements for AppendEntries RPC from all the follower nodes. Thus the write quorum will be full, and logs will stay identical on all the nodes. Hence, log matching property (and the above invariant) will be preserved in a glitch free system. As I mentioned in Part1, there is going to be no need for a re-election as the leader will be up and running, and sending out heartbeat messages to maintain its authority throughout.
However, its hard to imagine such a distributed system, and failures are possible. The following are some of the failure scenarios that can lead to inconsistency in logs in Raft:
- One or more follower nodes might be unavailable when the leader sends out AppendEntries RPC, and thus the log entry will be missing from the log of such follower nodes 😦
- This by no means implies that log entry didn’t get committed. Raft uses majority.
- For example, consider a cluster of nodes N1, N2, N3, N4, N5 where N1 is the leader. For any log entry to be committed, it should be written in logs of 3 or more nodes. So, even if N2 and N3 are down, a log entry can still be committed if it was written successfully in the logs of N1, N4 and N5.
- A follower node might be available to receive the AppendEntries RPC message from leader, but it may crash before writing to the log 😦
- All the nodes are up and running, but the system got network partitioned thus preventing the delivery of RPC messages to some nodes 😦
- The paper indicates that upon receiving a write request from client, the leader first does a local write before sending out the RPC messages to the follower nodes for replication.
- This gives rise to another possibility of failure. The leader node might crash after writing to its local log, but before sending out the RPCs to the follower nodes 😦
- A follower node N was unavailable during a series of writes replicated by the leader to other (alive) follower nodes. N might not have had a permanent failure. May be it was just a temporary glitch, and the node was not fenced from rest of the nodes in the cluster. Hence, N can become available after a while, and be a part of the cluster with its inconsistent log.
- There is a possibility that if the leader doesn’t use any strategy to detect inconsistency, it can continue to replicate the future writes to N’s log, thus ignoring the inconsistency 😦
- There is a possibility that N might be elected a leader in the future. Congrats !!, the system now has a coordinator node whose own log is not the latest one 😦
When such events happen, the system can be in one or more of the following states:
- Some follower node(s) may not have log entries that are present on the leader and other follower nodes — See points 1, 2, 3, and 4 above.
- The leader node may not have log entries that are present on the follower nodes — See point 5 above. We basically elected a bad leader.
- Both of the above.
There are couple of mechanisms employed in Raft to ensure that logs are consistent, and log matching property is never violated.
Mechanism 1 – A consistency check done by the leader during AppendEntries RPC.
- How does leader detect inconsistency – As part of AppendEntries RPC message, the leader sends the index (i) and term # (t) of last entry in its log that immediately precedes the new entry. If a follower node does not find an entry in its log with index (i) and term (t), it rejects the AppendEntries RPC. For example, see the below diagram. An entry is represented as <index #, term #>. Commands or client requests are not shown.
- As part of this consistency check, leader node sends out <i, t> as <5, 3>as the index and term of last entry that will precede the new incoming entry.
- There is a match with follower 1, but follower 2 rejects the request.
- If we analyze this from the beginning, induction is applicable over here as mentioned in the paper. At bootstrap, there is nothing in the logs:
- Entry <1, 1> is replicated. There was no preceding entry. Log matching property preserved.
- When sending out RPC for <2, 1>, leader node sends out <i, t> as <1, 1>. Match successful and entry <2, 1> is replicated. Log matching property preserved
- When sending out RPC for <3, 1>, leader node sends out <i, t> as <2, 1>. Match successful and entry <3, 1> is replicated. Log matching property preserved
- This continues, but replication of entry <5, 3> fails on follower 2 possibly due to some failure scenario as I mentioned above.
- The missing entry <5, 3> leads to the rejection of subsequent request from the leader.
- Note that all of the entries in the log are committed. Entry <5, 3> is also committed as it is present on majority (2) of servers in the cluster.
- We can say that whenever AppendEntries RPC return successfully from a follower, it implies logs of leader and follower are identical as of that point in time, and the log matching property is preserved as the logs are extended as part of replication.

- What does leader do after consistency check fails – The leader node maintains a nextIndex[] array to hold the log index for the new entry, it needs to send (as part of AppendEntries RPC) to each follower. When a node gets elected as leader, the array is initialized as (last index in leader’s log + 1). Similarly, at bootstrap when the cluster is being started and some node gets elected as the leader, the array will be initialized to 1. Let’s take the above diagram :
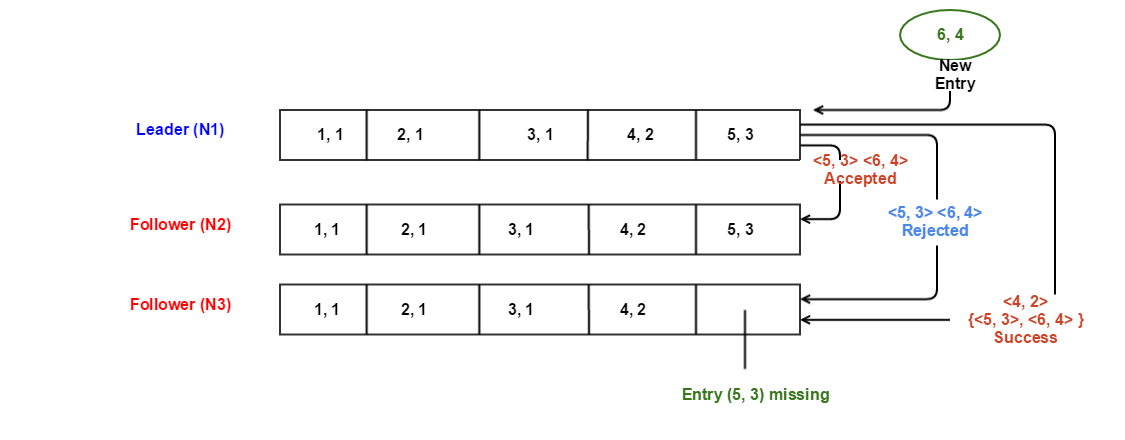
- N1 is the new leader for term 4. Let’s say there was a temporary glitch when N1 didn’t receive the heartbeat message from N2 (leader for term 3), started a new election for term 4 and became the leader. N2 is still up and running.
- All of the log state shown above is as of term 3 where N1 and N2 have consistent logs.
- The new incoming entry is <6, 4> that N1 will replicate on the followers.
- Because N1 just became the leader, it will initialize the nextIndex[] as {6, 6} for N2 and N3.
- N1 sends AppendEntry RPC to N2 with data as <5, 3> and <6, 4>. The former is used for consistency check, and the latter one is used by N2 to append to its log if the consistency check succeeds. Logs match and <6,4> is successfully replicated on N2.
- N1 sends AppendEntry RPC to N3 with data as <5, 3> and <6, 4>. Consistency check fails as the last entry in N3 is <4, 2> and not <5, 3>. N3 sends back the rejection to N1.
- N1 then decrements the nextIndex for N3 to 5, and retries the RPC with data <4, 2> and { <5, 3>, <6, 4>}. If this consistency check succeeds, N3 will append the log entries <5, 3> and <6, 4> in its log. As <4, 2> is the latest entry where logs of N1 and N3 match, the consistency check succeeds, and the entries are replicated successfully.
- If the above consistency check with N3 failed again (possibly because <4, 2> is also missing from N3), N1 would have further decremented the nextIndex and retried the RPC. This repeats until logs converge.
- Once the RPC returns “success” from a follower, leader updates the value in nextIndex[] array for the corresponding follower.
The above diagrams and scenarios describe how some inconsistencies in follower’s log are detected and handled by the leader. But, do we know that leader is up to date ? In other words, does the newly elected leader have all of the log entries committed in previous terms by old leaders ?
When can such a scenario happen ? Let’s take the below diagram with the following state:
- N1 is the new leader for term 4.
- N2 was the leader for term 3.
- N3 had a glitch, and is having an inconsistent log. N3 is back alive. N3 knows the current
- Let’s say there are no new client requests for term 4, but still N1 will periodically send out heartbeats to maintain its leadership. As part of this heartbeat, N3 will learn the new term, and will update its term # to 4.
- Now let’s say N3 does not receive the heartbeat message, and times out.
- Increments the term # to 5.
- Starts an election for term 5.
- The goal is to prevent N3 from winning the election. It does not have all of the committed log data from previous terms. Hence, it can’t be the leader. This is where the second mechanism comes in.
Mechanism 2 – Restriction on Voting and Leader completeness to preserve the following safety property.
Safety Property 4 – The leader for any given term contains all of the entries committed in previous terms.
In Raft, there is no need to transfer/ship missing data to the leader after the election. The below restriction on “who all can be the leader” ensures that from the time of election, leader will contain all of the earlier committed data.
As part of RequestVote RPC, the candidate node will send out <i, t> as the index and term # of the last entry in its log. A follower node will deny the vote to candidate if its own log is more up to data than candidate’s log.
- The follower node will compare the term # m of the last log entry in its own log to term # t received from candidate.
- If m > t, vote is denied.
- If m is same as t, then length of 2 logs will be compared. If len (candidate’s log) < len (follower’s log), vote is denied.
- Looking at the above diagram, we can see that neither N1 nor N2 will grant vote to N3 🙂
Just like there is no need to transfer log entries to the leader after election, a leader never has to overwrite or delete entries in its own log. A leader always appends new entries to its log.
Safety Property 5 – Leader always appends new entries to its log. Existing entries in leader’s log are never overwritten or deleted.
Having discussed the leader completeness property and restriction on voting, I will now give some insight into the most important property for the correctness of state machine replication:
- All servers should feed the commands from their logs into respective state machines in the same order — in the log order.
- This doesn’t mean that all servers will apply a particular state machine at the same time. Server 1 might do entry 1 -> entry 2 -> entry 3 whereas server 2 might have applied only entry 1 -> entry 2. The order of applying is still the same.
The goal is to maintain the following property:
Safety Property 6 – If a server S1 applies the committed log entry ‘e’ at index i to its state machine SM1, then no other server can apply a different committed log entry at index i to its state machine SM2.
This can be derived from the leader completeness and log matching properties. Once a server applies a committed entry ‘e’ at index ‘i’, it is guaranteed to be present in the logs of current and any future leader(s).
In my follow up post, I would like to cover some interesting failure scenarios with more diagrams to bring more clarity w.r.t correctness of replication and commitment of entries. I haven’t talked about how the client communicated with Raft system, and idempotent nature of RPCs. This will also be discussed in the next post. Stay tuned !!
Back to Part 1
References:

Leave a comment