
In this post, I will talk about two critical components of Raft consensus algorithm. My post will majorly focus on the explanation of these concepts as I interpreted from this extremely good paper on Raft. Of few papers I have read, it is one of the most well written paper on distributed systems and related topics.
Introduction to Raft
Raft is a consensus algorithm for implementing fault tolerant distributed systems using a replicated state machine approach. Consider the distributed system to be a cluster of machines or servers. There needs to be a some fault tolerant strategy/algorithm that makes these machines operate as a single unit such that each server executes the client’s commands, transactions in a consistent manner. In a distributed system built with replicated state machine approach, each server runs a deterministic state machine that:
- Has a given state.
- Takes some command(s) as inputs.
- Generates output(s).
- Moves on to a new state after generating the output.
The goal is to have each server feed the same sequence of input commands into its state machine such that it generates the same output(s) and new state after processing the input commands on each server. This is why we say that each server runs a deterministic state machine — two different deterministic state machines when fed the same set of input commands in the exact same order will produce identical output state.
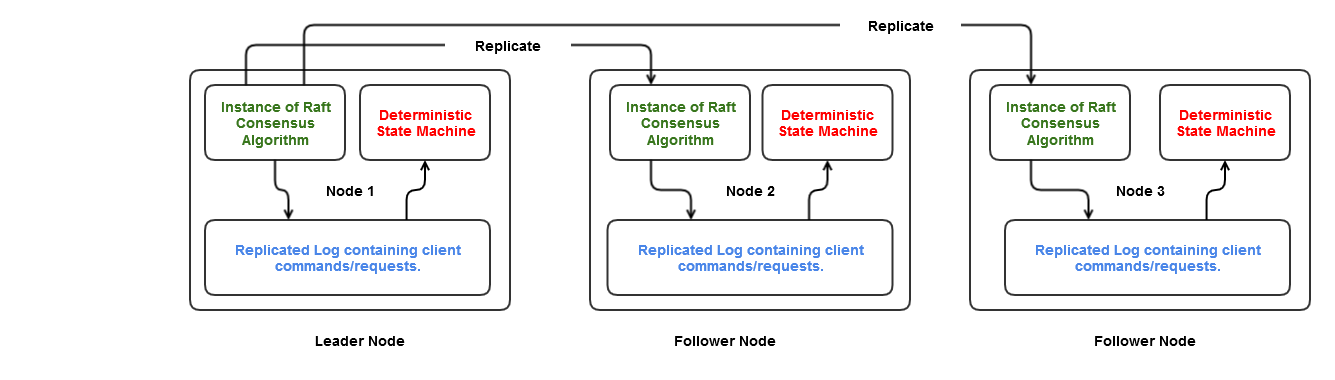
How do we achieve this ? This is where consensus or agreement algorithm has a huge role to play. At the heart of raft consensus algorithm is a persistent log containing commands issued by the client. The job of the consensus algorithm is to consistently replicate this log across all the servers in the cluster. The log on each server is the source of input commands for their respective state machines. A distributed system built with Raft can be imagined as:
- Each server in the cluster runs an instance of Raft consensus module and has a persistent log to store the commands received from client.
- The consensus module on a server receives commands from client, adds them to the local log, and communicates with the consensus module running on other servers to consistently replicate the command(s) onto their logs in a way that they are stored in the same order in all the logs.
- Each server feeds (in the same order) the input commands from its local log into its state machine engine, generates same output state and appropriate result is returned back to the client.
Raft is built around a centralized topology of the distributed system. It has a leader-follower like architecture, and fault-tolerant leader election mechanism is very very important for the overall correctness of the consensus algorithm. Note that this is very different from Paxos. In this paper, Leslie Lamport makes it very clear that electing a distinguished proposer/learner is a sort of an optimization, but is not necessarily important for the correctness of Paxos algorithm. But in Raft, leader election is a core part of the consensus algorithm itself. I am not going to compare or sight differences between Paxos and Raft in this post. I plan to do that in a separate article.
So, let’s focus on Raft, and take a stab at leader election.
Leader Election in Raft
Each server in a Raft cluster is in one of the following states at any given point of time:
- Follower – All except the leader node are the follower nodes in the cluster.
- Candidate – Contestant for leader election
- Leader – Node that accepts client requests, manages the replication of log, determines when the log data is committed etc.
Time period in Raft is divided into terms of arbitrary length. Each term is identified by a term # ; a monotonically increasing number, and initialized to 0 at server startup time. Each term begins with a new leader election where one or more candidate nodes compete to become the leader. Once a candidate wins the election, it serves as the leader for that particular term. This leads us to the first safety property of Raft algorithm:
Safety Property 1 – For any given term, there can be at most 1 leader.
In a glitch free system, the system will progress forward in the same initial term – term 0. The leader elected at the cluster startup will continue to operate as the leader happily throughout the life. There is no doubt that it is hard to imagine and believe that system will be glitch free.
Current term number known to a server forms a part of the persistent information maintained by the server. The ongoing latest term number is exchanged between the servers as part of RPCs allowing a server having a stale/old term number to update to the latest (larger) term number. The term number is also encapsulated as part of requests sent by the leader to follower nodes. A node rejects any request received with an old term number.
The leader node periodically sends heartbeat messages to the follower nodes indicating that leader is alive, and there is no need for an election. Every follower node has a “election timeout” T which triggers the beginning of new term and leader election. If a follower node doesn’t receive the heartbeat message from the leader within this timeout period :
- It assumes that leader has failed or crashed.
- Increments the current term number.
- Changes its state to Candidate.
- Votes for itself and requests votes from other follower nodes by sending out RequestVote RPCs in parallel to all the follower nodes.
A candidate node wins the election for the term once it receives votes (responses to RequestVote RPC) from majority of nodes in the cluster. This brings us to the second safety property:
Safety property 2 – A server will vote for at most one candidate for the particular term. This will be done on first-come-first-served basis.
Once a candidate wins, it establishes its authority over other follower nodes by broadcasting a message to all other nodes. This will let everyone know who the new leader is. It is quite possible that multiple servers timeout in close proximity. While a candidate is waiting to receive votes/responses for RequestVote RPC, some other candidate might have won the election for the same term. For example:
Consider a cluster of node N1, N2, N3, N4, and N5.
- Current term = 5.
- N5 is the current leader.
- N1, N2, N3, N4 are follower nodes.
- N5 fails.
- N1 and N2 detect this.
- N1 and N2 increment the term # to 6 and send out RequestVote RPCs to remaining nodes. The cluster now has concurrent elections. Under the assumption that N2’s RPC arrived at N3 and N4 before N1’s RPC, safety property 2 ensures that N3 and N4 will give their vote to N2 , and will not cast any other vote for term 6.
- N2 receives back the responses from N3 and N4 and declares itself as the leader by broadcasting a message along with the term number 6.
- N1 who is still a candidate receives this message and learns that N2 is claiming itself to be the leader for term 6. N1 reverts back to the follower stage.
- The cluster has its new leader as N2.
A slightly different scenario is also possible for the same cluster.
- Current term = 5.
- N5 is the current leader.
- N1, N2, N3, N4 are follower nodes.
- N5 fails.
- N1 detects this. Increments the term # to 6 and sends out RequestVote RPC to remaining nodes.
- Meanwhile N5 is back alive. It doesn’t know that election is going on for the next term. N5 still thinks he is the leader.
- N5 receives client request and sends out the corresponding RPCs with term # 5 to rest of the nodes. Note that this RPC is related to Log Replication and will be discussed in detail in Log Replication section.
- Every node rejects this request as it contains a stale term #. N5 learns the new term # 6, and immediately reverts to follower stage.
- N1 receives the votes, and broadcasts the message establishing its authority.
- The cluster has its new leader as N1.
Another interesting scenario is split vote.
- Current term = 5.
- N5 is the current leader.
- N1, N2, N3, N4 are follower nodes.
- N5 fails.
- N1 and N2 detect this.
- N1 and N2 increment the term # to 6 and send out RequestVote RPCs to remaining nodes. The cluster now has concurrent elections.
- Both N1 and N2 have 1 vote (self vote) each as of now.
- Let’s say N1’s RPC reaches N3 followed by N2’s RPC. As per safety property 2, N3 will give its vote to N1.
- Let’s say N2’s RPC reaches N4 followed by N1’s RPC. As per safety property 2, N4 will give its vote to N2.
- Both N1 and N2 have 2 votes each. For winning, one should get 3 votes which obviously doesn’t seem to be possible. Hence, we have a split as no one won the majority.
- In such cases, the candidates will time out again, term 6 will end without a leader, and a new election will be started for the new term.
Once a split vote happens, it can happen again and this can go on forever. In the above example, both N1 and N2 will timeout again after the split, and will start the new election. A split can happen again. Raft uses randomized timers to minimize the probability of concurrent elections. Each node will get its value of election timeout in a random manner such that in most cases only a single server times out, becomes the candidate, and quickly completes the election before any other follower times out.
Also, at the beginning of election, every candidate will reset its timer. So, in case we get a split, one candidate will timeout before the other candidate and start the second election before the other one does. Still, there is no guarantee that splits won’t happen ever with the these measures. I do not have enough information to explain how exactly are split votes handled. Once I have meddled with an implementation, I can cover this as a separate post.
After going through the above scenarios and the mechanism of leader election, we can now draw the state diagram for nodes in a Raft cluster.

This completes the overview of election algorithm. We went through an introduction on Raft, couple of safety properties, and some election scenarios. There is still more to the election algorithm especially w.r.t correctness, along with some other very important safety properties. To discuss all of these, we need to first take a deep dive into Log Replication.
To limit the content per post, I will be discussing the remaining things in Part 2 very soon.
References:

Thanks for the detailed explanation Siddharth
LikeLiked by 1 person