")
With the advent of multi-core architectures, it is becoming increasingly important to build scalable data structures that support the basic operations (insert, search) without taking coarse grained locks. Coarse grained locks are usually taken on the entire data structure and prevent any other concurrent thread(s) from operating even on other disjoint/orthogonal parts of the data structure. Thus algorithms built on such locking scheme by definition are blocking in nature. An example of operation using coarse locks would be a method in Java with “synchronized” keyword. If a thread T is executing a synchronized method on a particular object, no other concurrent thread can invoke any other synchronized method on the same object. Thus thread T blocks other threads from accessing the data structure/object. The corresponding example in C/C++ would be a mutex lock that is taken (pthread_mutex_lock) at the beginning of a function and released (pthread_mutex_unlock) before the thread exits the function.
Data structures (and their corresponding methods) implemented with coarse grained locks are hard to scale in highly parallel environments and workloads where the structure is required to be accessed by several concurrent threads simultaneously (parallelism).
In this post, I will summarize my understanding of a non-blocking (lock free) design of linked list data structure as presented in paper “A Pragmatic Implementation of Non-Blocking Linked-Lists” by Tim Harris.
The paper presents the design (and pseudo code) of a lock free linked list data structure that supports concurrent insert(), delete() and search() operations without taking explicit locks/mutexes etc. The proposed algorithms leverage CAS (Compare and Swap) low level atomic instruction to implement lock-free methods on linked list.
CAS is an atomic instruction available on all modern processors. The post will use the following semantics of CAS.
bool CAS (memory location L, expected value V at L, desired new value V1 at L).
If the expected value at memory location L matches with the current value at L, CAS succeeds by storing the user desired value V1 at L and returns TRUE.
For the following discussion, we will assume that linked list is sorted and take the following simplest definition of a linked list node.
typedef struct node
{
int element;
struct node *next;
} node;
Note: The paper obviously proposes its own generic linked list type and node definitions. However, I feel the above mentioned simple definition is good enough to understand the main ideas (lock free algorithms) proposed in paper. Everything else is just low level implementation detail which the reader shouldn’t really care about.

Insert Operation – Insert new node with value 7 in the linked list structure shown above.
The generic algorithm to insert a new node into a sorted linked list is:
- Traverse the linked list from head to find the largest node strictly smaller than value 7 (due for insertion). Let this node be N1.
- The node pointed to by “next” pointer of N1 is N2.
- We allocate a new node N and insert it between N1 and N2 as follows:
node* N = (node *)malloc(sizeof(node)); N->element = 7; N2 = N1->next; N->next = N2; N1->next = N;
The above code snippet will effectively change the structure of linked list by creating and allocating a new node N between N1 (node with value 6) and N2 (node with value 10). This operation (specifically the act of changing the “next” pointer of N1 to point to new node N) needs to be atomic. The paper suggests the following simple approach to implement insert() in an atomic manner using CAS:
N->next = N2;
ret = CAS(&(N1->next), N2, N);
if(ret)
{
// CAS succeeded. N was successfully inserted between N1 and N2
return true;
}
else
{
// CAS failed.
// retry
}

CAS will fail if the “current” value at memory location is changed concurrently.
- In the context of this example, the “current” value at memory location “N1->next” is address of node N2. So if some other thread beats us by concurrently inserting a new node between N1 and N2 , CAS will fail because the reference stored in “N1->next” will no longer point to node N2.
- For example, if some other concurrent insert operation successfully inserted a node with value 9 between nodes with value 6 and 10, our CAS operation to insert node with value 7 will fail. This scenario is shown in the following diagram (Please ignore nodes labelled as H and T. The reason for having those nodes will be explained very soon).
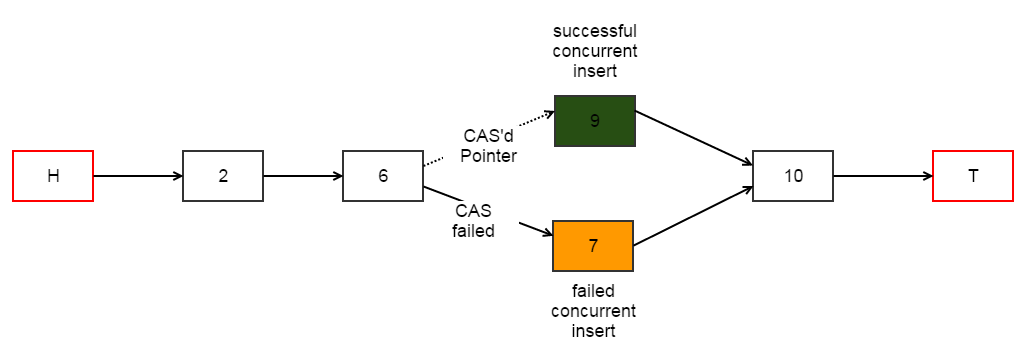
Because we are no longer taking explicit locks, there is no guarantee that insert operation will succeed. Therefore, CAS based algorithms are usually implemented using a loop (aka CAS loop) to retry the operation when CAS fails. The pseudo code for insert operation will now look like:
Assumption: The node to be inserted is not already in the list. This corner case is not addressed right now.
boolean insert(int ele)
{
// CREATE AND INITIALIZE THE NEW NODE N (DUE FOR INSERTION)
node *N = (node *)malloc(sizeof(node));
N->element = ele;
N->next = NULL;
node *N1 = NULL;
node *N2 = NULL;
// CAS LOOP
do
{
// SEARCH FOR THE ELEMENT, get references to N1 and N2 nodes
N2 = search(&N1, element);
// CHECK ELEMENT SHOULD NOT ALREADY EXIST - IGNORE THE CORNER CASE FOR NOW
N->next = N2;
// SWING THE POINTER OF PREDECESSOR - ACTUAL STEP THAT INSERTS THE NEW NODE
if(CAS(&(N1->next), N2, N))
{
// CAS SUCCEEDED - INSERT DONE
return TRUE;
}
}
while(TRUE);
}
The insert() operation internally uses the search algorithm to traverse the linked list and get references to nodes N1 and N2. There are some important details missing from the above description and code example(s). I will get back to them after discussing delete() and search() operations as then it will make much more sense to discuss more details, questions and concerns.
The insert() operation on a linked list can be divided into three cases: (1) insertion before head, (2) insertion after tail and (3) insertion in the middle.
The CAS based approach takes care of all these cases. Until now what we have discussed is case (2) which deals with inserting a new node with value 7 between existing nodes with value 6 and 10 respectively.
We can address cases (1) and (3) by converting them to case (2). This is possible by keeping dummy head and tail nodes that contain no meaningful value. The paper calls these as sentinel nodes but doesn’t discuss the reason for having them in the linked list. However, I feel these dummy/sentinel nodes are needed to conveniently handle cases (that change head and tail) in the form of case (2). So with dummy nodes H and T, the state of linked list will be:

Note that H and T are not the logical “head” and “tail” nodes of linked list.
How does this help in handling cases (1) and (3) ?
- Inserting before head — effectively inserting a new node between dummy node H and current head node (node with value 2).
- Inserting after tail — effectively inserting a new node between current tail node (node with value 10) and dummy node T.
Delete Operation – Delete existing node with value 7.
The generic deletion algorithm from a sorted linked list is:
- Traverse the linked list from head to find the largest node strictly smaller than 7. Let this node be N1.
- The node pointed to by “next” pointer of N1 is N2 (due for deletion).
// REMOVE N2 FROM LIST N1->next = N2->next; free(N2);
CAS based approach:
N3 = N2->next;
// SWING THE "NEXT" POINTER OF PREDECESSOR NODE
ret = CAS(&(N1->next), N2, N3);
if(ret)
{
// CAS succeeded. N2 was successfully removed from the list.
// "next" field in N1 now points to node N3.
return true;
}
else
{
// CAS failed.
// retry
}

The successful CAS operation that swings the “next” pointer of N1 to point to N3 only makes sure that N2 (node being deleted) is indeed the “next” node of N1 at the time CAS is executed. For example, if a concurrent insert() operation inserted a new node (with value 6.5) between nodes 6 (N1) and 7 (N2), our CAS of “next” pointer of N1 will fail while we are trying to delete node 7 (N2). This is completely fine and correctness is ensured.

The paper presents a very interesting problem associated with concurrent insert() and delete() operations. The single CAS operation doesn’t detect any changes happening after node N2 (due for deletion). In other words, as part of delete() when we swing the “next” pointer of N1 to point to N3, there is really no guarantee that N3 is in fact the successor to N2.
For example, if a concurrent insert() operation successfully inserts a new node with value 9 between nodes with value 7 (N2) and 10 (N3) respectively, our CAS operation will still succeed but will lead to an inconsistent (and corrupt) state of linked list. The following diagram shows this. CAS succeeds and swings the “next” pointer of N1 (6) to point to N3 (10). However, a concurrent insert happened after N2 (7) and N3 (10) was no longer the true successor to N2. Linked list is corrupted because even though node with value 9 is a valid node in the list, we have no reference pointing to it. It should _not_ be missing from the list.
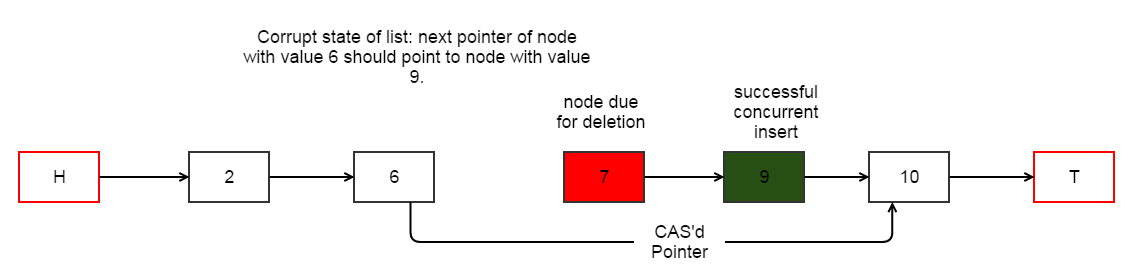
To solve this problem, the paper introduces the concept of “marking” (or tagging) the node X that is due for deletion. Tagging a node X prevents the insert() operation to insert a new node Y as a successor to X.
When we use tagging, deletion happens in two steps (two CAS operations) — marking and removing. We mark a node by setting the LSB in its “next” pointer. Note that pointers are always aligned. So the LSB is available for such use. If the LSB of 8 byte reference stored in “next” field of a node N is set, it implies that N is marked (and someone intends to delete it).
Assumption: The node to be deleted is already in the list. This corner case is not addressed right now.
boolean delete(int ele)
{
// CAS LOOP
do
{
node *N1 = NULL;
node *N2 = NULL;
node *N3 = NULL;
// SEARCH FOR THE ELEMENT, N1, AND N2 nodes.
N2 = search(&N1, element);
// CHECK ELEMENT SHOULD ALREADY EXIST - IGNORE THE CORNER CASE FOR NOW
N3 = N2->next;
// STEP1 -- TAGGING, MARK THE "NEXT" POINTER OF N2 (THE NODE TO BE DELETED)
if( CAS(&(N2->next), N2->next, MARK_POINTER(N2->next)))
{
// IF WE ARE HERE, MARKING WAS SUCCESSFUL -- LSB set
// STEP 2 -- SWING THE "NEXT" POINTER OF PREDECESSOR NODE TO REMOVE N2
ret = CAS(&(N1->next), N2, N3);
if(ret)
{
// CAS SUCCEEDED. N2 was successfully removed from the list.
// "next" field in N1 now points to node N3.
return true;
}
}
}
while (TRUE);
}
Using the two-step approach for removing a node, the “linked list corruption” problem is solved because tagging node N2 (7) will prevent the concurrent insert of node with value 9 as a successor to N2.
The success of first CAS in the delete() algorithm ensures that node 7 has been marked for deletion (intent to delete) and any other concurrent insert() operation will not be able to insert a new node after node 7. Since the second CAS is executed only if the first CAS succeeds, it guarantees that the pointer swing (N1->next = N3) is not going to make the list inconsistent.
One of things that is confusing from the paper is the memory reclamation. The paper mentions that node removal comprises of two steps (1) logical deletion when the node is tagged by first CAS and (2) physical deletion when the “next” pointer of predecessor node is swung by second CAS.
I disagree here. Physical removal of the node is somewhat related to memory reclamation. The node is still there in a valid memory location because no free() or delete() call has been made to release the memory back to heap. Step (2) only ensures that node is not part of the list and in my opinion this is completely different from actually reclaiming the memory associated with the node.
It turns out that they use some reference counting based algorithm for memory reclamation to ensure that memory is reclaimed only after it is guaranteed that _no_ readers are holding any references to those nodes.
I haven’t discussed the full paper yet. Since I don’t like very long posts, I will cover the search() algorithm and various concurrency scenarios on all three (insert, search and delete) algorithms in my follow-up posts. Stay tuned 🙂
I would highly recommend reading the paper. It is a wonderful read.

Hi,
> (1) insertion before head, (2) insertion after tail and (3) insertion in the middle.
should read
> (1) insertion before head, (2) insertion in the middle. and (3) insertion after tail
LikeLike
Hi Kevin, Thanks. I will make the correction. Hope you liked the post.
LikeLike
Linking HN comments to this post – https://news.ycombinator.com/item?id=13892581
LikeLike
Thanks Ashwin 🙂
LikeLike
There are two things which can resolve this:
1. Have an isolation level (define what can be locked) and what shouldn’t be
2. Somehow the concurrent thread must have access to the most recent state of the structure so that the thread is smart enough to understand. I do not agree to the fact of re-trying the action when it failed earlier because the state has changed.
LikeLike
Can be inspect, compare and swap
ICAS. 🙂
LikeLike