")
Eventual Consistency in a shared data replicated distributed system implies the following:
- A read operation R on data object X is not guaranteed to return the value of most recent completed write operation W on data object X.
- Alternatively, in a distributed system based on eventual consistency, it is possible for the readers to see stale (not the most recent) copy of data.
Eventually all the nodes (replicas) storing copy of object X will converge to a single consistent copy and once this happens, readers will start seeing the most recent copy of data regardless of the node handling the read operation. Since such a state of the system is not guaranteed to be true at all instances of time, the semantics of consistency are “eventual” or “relaxed” implying that system will eventually reach such state.
Such consistency semantics are preferred to increase availability and lower the operation latency. Relaxed consistency semantics do not require the update operation to be visible/applied on each replicas of the data object. The system takes care of converging or syncing all the replicas in background (asynchronously) to a single consistent copy. Special algorithms have to be implemented to do this. The fact that this doesn’t happen on the critical path (client request) is the fundamental reason for improved availability and performance of the system since the request can complete even when some nodes are down (high availability) and the update operation can be potentially completed by executing on fewer replicas (low latency).
Discussing this in the context of CAP theorem, systems that exhibit eventual consistency semantics are typically classified as “AP” systems. However, this classification gives an impression that such systems prefer availability over consistency only in the presence of network partitions, faults etc. In my opinion, this is not always true. Distributed systems based on the principles of eventual consistency are “relaxed” about consistency requirements right from the beginning typically because they care more about high availability and low latency. They really don’t have to wait for the first fault to happen and then change the consistency semantics of the system.
R, W and N – These are configuration parameters typically used to set the consistency levels of distributed system. In most cases (Cassandra and Riak), they are tunable and thus developers writing applications on top of distributed data stores can set these to appropriate values depending on the use cases.
- N – Replication Factor
- W – Minimum number of replica nodes that should acknowledge a write request for the system to declare the operation as successful.
- R – Minimum number of replica nodes that should acknowledge a read request for the system to declare the operation as successful.
Generally speaking, if the system has configuration R + W > N, we get strong consistency since the replica sets participating in read and write operations will always overlap (QUORUM). Thus a “successful” read request is guaranteed to return the result of most recent write since the request will always touch at least one replica that has the most recent copy of object.
Let’s take a simple system for discussion. The following diagram shows a 3-node distributed system.

N = 3, R = 2, W = 2 ; R+W > N
Write (item X, value V)
- A write operation is typically sent to all nodes regardless of the value of W. W controls the “minimum” number of successful responses that should be received by the coordinator node before it can return back to client with “SUCCESS”.
- Let’s say the item was successfully written on nodes N1 and N3 but the coordinator node couldn’t receive a response from N2.
- Since write quorum (W is 2) is anyways met, the update is successful.
- It is not absolutely necessary for the coordinator node to be a part of replica set. It can be an entirely different node in the cluster.
- In this example, N1 coordinates the update operation for item X.
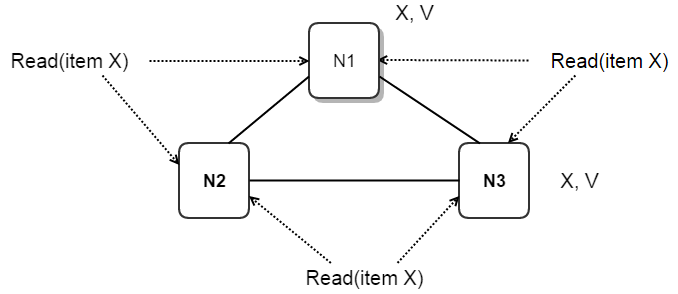
Read (item X)
- Any subsequent successful read operation will touch at least two (read quorum) nodes from set {N1, N2, N3}.
- Hence it will see the latest value of item X regardless of the fact that latest update to item X is not yet propagated/replicated to N2.
- The distributed system’s implementation of read algorithm should have a way to ensure that copy present on N1/N3 is the latest one and N2 doesn’t have the change yet (or has the outdated change).
- How exactly this happens will not be discussed in this post since this topic deserves good details and will be covered in follow-up posts.
Now let’s consider a different state of the system to demonstrate eventual consistency. Let’s say all replicas N1, N2 and N3 store value V for object X to begin with. Consider this as the starting state for the sake of discussion.

Let’s take N = 3, W = 2, R = 1 ; R + W <= N
Write (item X, value V1)
- Nodes N1 and N2 meet write quorum and update the value of item X to V1.
- Node N3 still has the old copy (value V).

Read (item X)
- Let’s say the operation was coordinated by N3.
- Since N3 is also one of the replicas for item X and R is 1, it returns “SUCCESS” with result as V — client sees a stale value.
- This is the point where we see the effects of eventual consistency — a read() doesn’t see the changes of most recent write() simply because the latest changes haven’t yet been propagated to node(s) handling the read request.
- On the other hand, if N1 coordinates the read, the client will see the latest changes.

This behavior is the fundamental characteristic of an eventually consistent system. It is strikingly different from what we saw earlier in a strongly consistent system (R+W > N) — the set of nodes required to participate in a successful read operation will have at least one node with the latest copy of data.
Consider the same system with R as 2 instead of 1. All readers see the latest changes and we again get a strongly consistent system with R + W > N.

For a strongly consistent system with W = N, R can be 1 — any replica can serve the read request and is guaranteed to have the most recent copy of data. But this configuration increases the latency of writes since the operation will touch all nodes. It also reduces availability since the write operation will fail even if one node is down.
Highly Available Configuration with Eventual Consistency
W=1 and R=1 (W + R <= N) has the potential to be a highly available system with low latency operations. A read and write will succeed as long as even one node is available in the system.
In my follow up posts, I will talk more about consistency semantics, update conflicts, asynchronous replication and time-stamps. Stay tuned 🙂

Leave a comment