
In this very short post, I will give an overview of primary and secondary indexes in Databases.
DISCLAIMER: I am an Oracle employee, and the views/opinions expressed in the below article are purely my own and do not express the views of my employer.
Let me tell the similarities first:
Similarities
- Both the index structures are implemented as separate first class objects (typically as disk based B-Tree structures) in the database. This implies that table and its corresponding index (primary or secondary) exist as two separate structures.
- Both implement a level of indirection where the queries first lookup the index, and use the result of this lookup to directly fetch the actual record it is pointing to.
- Index blocks in both types of indexes keep the entries sorted ; i.e whatever the actual index entry is → something like<index key, row locator>. The entries in the index block are always sorted on the index/search key. A row locator in a database encapsulates complete information required to fetch/access a particular row from disk or memory in a database system. Different databases may have their own variations and implementations of row locators and index entries.
Differences
Primary Index
- A primary index impacts the storage and organization of rows in data blocks. Data blocks are disk blocks that store the actual row data (multiple columns).
- Primary Index requires the rows in data blocks to be ordered on the index key.
- So apart from the index entries being themselves sorted in the index block, primary index also enforces an ordering of rows in the data blocks.
- The below diagram borrowed from “Database System Implementation by Garcia Molina et al” shows how the index entries in the index blocks (left side) contains pointers (these are row locators in database terminology) to corresponding rows in data blocks (right side). Each data block has rows in sorted order as per the index key.
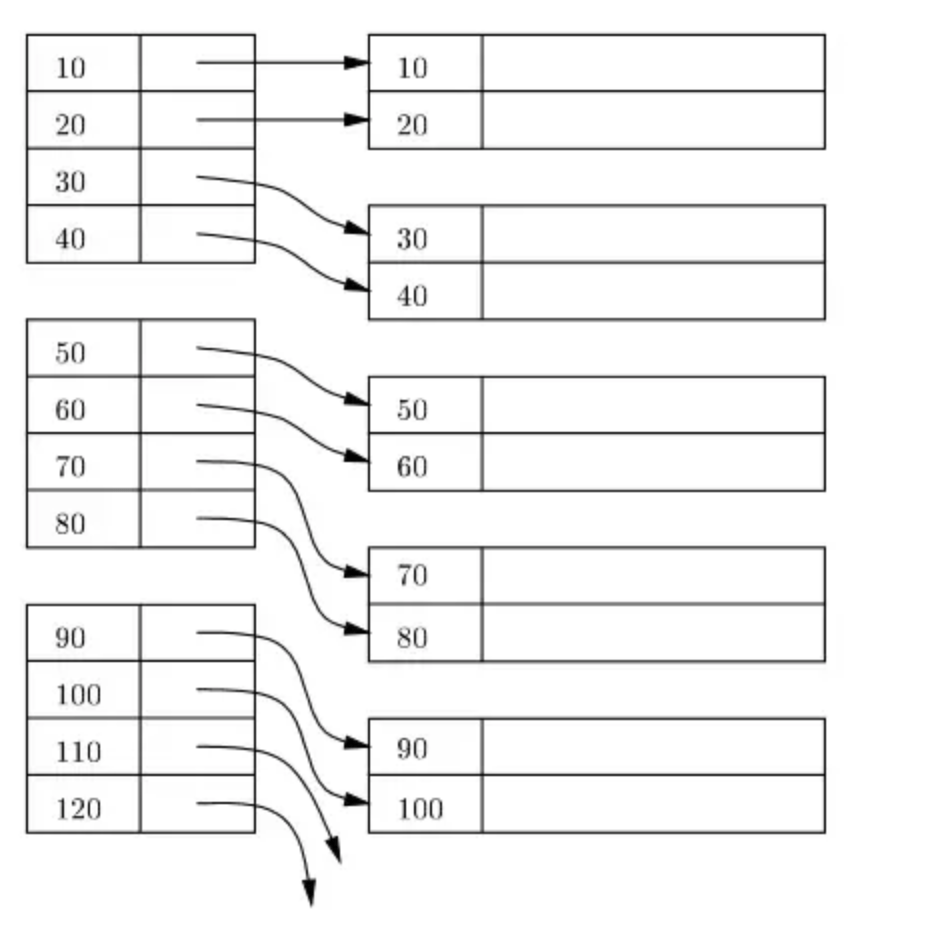
- Primary Index can be created on both key and non-key columns. There is no such thing as primary index is meant only for primary key. But, yes usually it is created on the primary key of table.
- Since primary index alters the way (needs to keep the rows sorted) data is organized in a table, there can be at most one primary index on a given table.
Secondary Index
- Secondary Index does _not_ have any impact on how the rows are actually organized in data blocks.
- They can be in any order. The only ordering is w.r.t the index key in index blocks.
- The below diagram borrowed from “Database System Implementation by Garcia Molina et al” shows how the index entries in the index blocks (left side) contains pointers (these are row locators in database terminology) to corresponding rows in data blocks (right side). The data blocks do not have rows sorted on the index key.

Comparison
- Firstly, the user can define multiple secondary indexes because they have no impact on the organization of rows in table. But there can be only a single primary index on a particular table.
- Because primary index does not necessarily have to be on primary key, primary index can also have duplicate index keys. In fact the example shown above for secondary index is for duplicate keys. So both primary and secondary indexes can be UNIQUE and NON-UNIQUE.
- Obviously if the primary index is created on primary key, then there can’t be duplicate index keys since primary key enforces a UNIQUE CONSTRAINT.
- Both primary and secondary indexes can be used for point lookups and range scans.
- Range scans are expected to be faster for primary indexes. This is because it enforces and ordering of rows in data blocks. Let’s say the range scan query is something like “SELECT FROM T …. WHERE KEY >= 20 AND KEY <= 50”. There is a primary index on column “KEY”. There are high chances of doing less physical I/O in terms of number of disk blocks being read because the arrangement of rows in data blocks is ordered on the index key.
- It is possible that all the rows belonging to keys in range [20,50] are in same data block or spread across less number of data blocks. This reduces the disk latency when reading the data block from disk
- On the other hand, because secondary index does not enforce any ordering of rows in data blocks, it is possible that each row belonging to key in range [20,50] is in a different data block thus incurring maximum physical I/O due to the increase in seek time on disk.
- Obviously if caching is playing a great role then most/all of the blocks will be cached in in-memory buffers of database. The I/O performance comparison becomes moot in case when all blocks are in buffer cache.
- But let’s say there is no caching and all the reads are direct reads (bypassing the buffer cache) then the performance difference is expected to be huge.
- The fact that range queries are expected to be faster for primary indexes is true for both UNIQUE and NON-UNIQUE indexes for the same reasons mentioned above.
- Point lookups (lookups by INDEX key) for UNIQUE indexes are expected to give same performance for both primary and secondary index. This is because such a SELECT will first probe the index to fetch the row locator corresponding to index key, and then use the row locator to access (and read) the data block having the corresponding row. There is no short-circuiting or additional code path in any case. Hence, the cost of lookup should be same in both cases.
- Point lookups (lookups by INDEX key) for NON-UNIQUE indexes are expected to be faster for primary indexes because of the same reason explained for “why range scans are faster on primary indexes”. The sorted order (by index key) in data blocks plays a huge role in determining the I/O cost.
- Because primary index forces the rows to be ordered in data blocks, DMLs will be less efficient. Because DMLs need to keep rows in sorted order within a data block, INSERT/UPDATE will cause frequent row movement (both intra/inter block row movement) unless the user takes care that inserts are done in a sequential order.
- Any DML that results in a row movement of a row within a data block will also require an update to corresponding primary index structure since the index entry <index key, row locator> now needs to be updated with new row locator (because the row was moved).
- Row movement will require an update to secondary index structure as well, but the probability of an INSERT causing a row movement is relatively low for secondary index since the INSERT does not need to keep rows in sorted order within a data block. Cases like row growing in size and thus requiring a move to all together a different block are one of the few cases of row movement in secondary index.
